Archive
Cheap Virtual Reality option
Probably you have eared about the Virtual Reality, and how companies like Oculus Rift are creating devices for that.
I am very interested on it, because it could improve a lot your gaming experience. However, I was quite disappointed about the prize (around 700 euros in Europe) and the minimum requirements to use Oculus Rift. In their web page you can download one software that will check if your computer is acceptable or not.
I started to investigate if there is a possible option to use your smartphone as a screen, I even though to develop something, but finally it was not necessary. The main issue I found is that there are people comments from the middle of 2015 and I didn’t find almost nothing from that date to nowadays (it is 23-01-2016 in the moment that I’m writing these lines).
I’m going to show you how can we play Project Cars game using our smartphone as a Virtual Reality screen and head tracker.
What software do you need
- Trinus VR. There is one server application for desktop and other for the client. Our client will be a Nexus 5 with Android 6.0.1. This application is going to redirect the image from your computer to your smartphone and it will be listening your inputs to do the head tracking. It also split the screen in two parts to provide the Virtual Reality effect when you insert your smartphone in a VR glasses.
- Opentrack 2.3. As I said, Trinus VR will be listening your inputs… but wait, what inputs?. It could be a mouse move, UDP packages incoming, etc. Theoretically, we don’t need this application, but I realized that the head tracking in Project Cars doesn’t work with Trinus VR. So I will use Opentrack to fix this problem.
- FreePIE IMU. There is no direct link to download. You will find this Android application inside the Opentrack 2.3. Instructions here. It is an APK that you will need to copy in your Android device and install it.
Physical devices
- Android smartphone that can run Trinus VR client and FreePIE IMU.
- PC that can run Project Cars and all the software mentioned with Windows 7 or higher.
- USB cable to connect your smartphone with your computer.
- (Optional) VR glasses to insert your smartphone.
Lets start
- Install all the required software.
- Plug your smartphone with USB to your PC.
- Run Project Cars in windowed mode, because it is mandatory for the Trinus VR display. Start any circuit in free practice for example and set the camera to the helmet view.
- PC: Run as an administrator, Trinus VR and Opentrack.
- Android: Run Trinus VR and FreePIE IMU, use the IP of your computer.
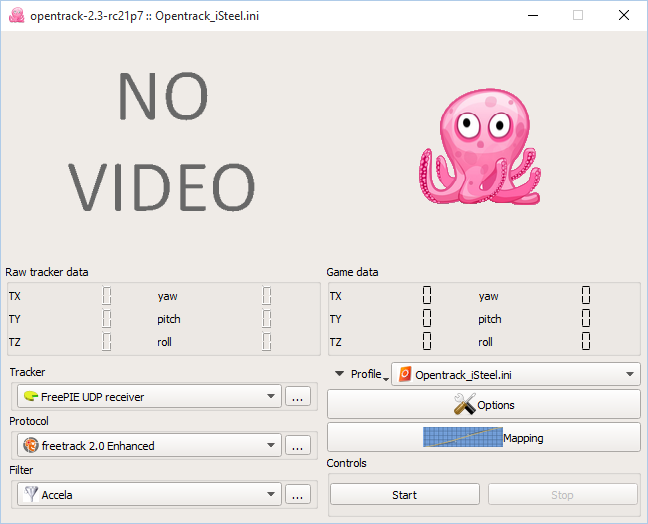
- Load the profile .ini (you will find it at the end of the post) in Opentrack and check the screenshots I attach.
- Make sure that the port value is the same as FreePIE IMU is using. Click start and if everything is fine, the octopus will move with the movement of your smartphone.
- Run Trinus VR with the configuration that you can see in the screenshots. It is important to set the Sensor output: Free Track.
At this point, you should see the game screen in your smartphone and the movements of the smartphone should be captured in the game.
One more thing. In my case, somehow Trinus VR starts to capture the inputs after clicking start in Opentrack and there is a mess because we have 2 programs setting the head track. There are two options:
- Stop the Opentrack.
- Set the sensor output in TrinusVR to no sensor.
Attachments





Profile .ini (Save this in a file with any name .ini and load it in the Opentrack as a profile)
[Curves-tx]
point-count=1
point-0-x=100
point-0-y=100
[opentrack-ui]
camera-pitch=0
camera-yaw=0
compensate-translation=true
compensate-translation-disable-z-axis=false
filter-dll=Accela
pitch-alt-axis-sign=false
pitch-invert-sign=false
pitch-source-index=4
pitch-zero-pos=0
protocol-dll=freetrack 2.0 Enhanced
roll-alt-axis-sign=false
roll-invert-sign=true
roll-source-index=5
roll-zero-pos=0
tracker-dll=FreePIE UDP receiver
tracker2-dll=
use-system-tray=false
x-alt-axis-sign=false
x-invert-sign=false
x-source-index=0
x-zero-pos=0
y-alt-axis-sign=false
y-invert-sign=false
y-source-index=1
y-zero-pos=0
yaw-alt-axis-sign=false
yaw-invert-sign=false
yaw-source-index=3
yaw-zero-pos=0
z-alt-axis-sign=false
z-invert-sign=false
z-source-index=2
z-zero-pos=0
button-center=-1
button-start-tracking=-1
button-stop-tracking=-1
button-toggle=-1
button-toggle-tracking=-1
button-zero=-1
camera-roll=0
center-at-startup=true
centering-method=1
guid-center=
guid-start-tracking=
guid-stop-tracking=
guid-toggle=
guid-toggle-tracking=
guid-zero=
keycode-center=F12
keycode-start-tracking=
keycode-stop-tracking=
keycode-toggle=
keycode-toggle-tracking=
keycode-zero=
[Curves-tx_alt]
point-count=1
point-0-x=100
point-0-y=100
[Curves-ty]
point-count=1
point-0-x=100
point-0-y=100
[Curves-ty_alt]
point-count=1
point-0-x=100
point-0-y=100
[Curves-tz]
point-count=1
point-0-x=100
point-0-y=100
[Curves-tz_alt]
point-count=1
point-0-x=100
point-0-y=100
[Curves-rx]
point-count=3
point-0-x=7.1999998092651403
point-0-y=8.7804880142211896
point-1-x=30.034286499023398
point-1-y=90.439025878906193
point-2-x=50.194286346435497
point-2-y=180
[Curves-rx_alt]
point-count=1
point-0-x=180
point-0-y=180
[Curves-ry]
point-count=3
point-0-x=6.9942855834960902
point-0-y=8.7804880142211896
point-1-x=30.034286499023398
point-1-y=91.317070007324205
point-2-x=49.7828559875488
point-2-y=180
[Curves-ry_alt]
point-count=1
point-0-x=180
point-0-y=180
[Curves-rz]
point-count=1
point-0-x=180
point-0-y=180
[Curves-rz_alt]
point-count=1
point-0-x=180
point-0-y=33.365852355957003
[Accela]
ewma=2
rotation-threshold=25
translation-threshold=25
[freepie-udp-tracker]
add-pitch-degrees=0
add-roll-degrees=0
add-yaw-degrees=0
axis-index-x=0
axis-index-y=1
axis-index-z=2
port=5555
[keyboard-shortcuts]
key-alt-center=false
key-alt-toggle=false
key-alt-zero=false
key-ctrl-center=false
key-ctrl-toggle=false
key-ctrl-zero=false
key-index-center=19
key-index-toggle=0
key-index-zero=0
key-shift-center=false
key-shift-toggle=false
key-shift-zero=false
[proto-freetrack]
use-memory-hacks=false
used-interfaces=0
[udp-proto]
ip1=127
ip2=0
ip3=0
ip4=0
port=5556
This other profile works much better for me:
[Curves-tx]
point-count=1
point-0-x=100
point-0-y=100
[opentrack-ui]
camera-pitch=0
camera-yaw=0
compensate-translation=true
compensate-translation-disable-z-axis=true
filter-dll=Accela
pitch-alt-axis-sign=false
pitch-invert-sign=true
pitch-source-index=4
pitch-zero-pos=0
protocol-dll=freetrack 2.0 Enhanced
roll-alt-axis-sign=false
roll-invert-sign=true
roll-source-index=5
roll-zero-pos=0
tracker-dll=FreePIE UDP receiver
tracker2-dll=
use-system-tray=false
x-alt-axis-sign=false
x-invert-sign=true
x-source-index=0
x-zero-pos=0
y-alt-axis-sign=false
y-invert-sign=true
y-source-index=1
y-zero-pos=0
yaw-alt-axis-sign=false
yaw-invert-sign=false
yaw-source-index=3
yaw-zero-pos=0
z-alt-axis-sign=false
z-invert-sign=true
z-source-index=2
z-zero-pos=0
button-center=-1
button-start-tracking=-1
button-stop-tracking=-1
button-toggle=-1
button-toggle-tracking=-1
button-zero=-1
camera-roll=0
center-at-startup=true
centering-method=1
guid-center=
guid-start-tracking=
guid-stop-tracking=
guid-toggle=
guid-toggle-tracking=
guid-zero=
keycode-center=F11
keycode-start-tracking=
keycode-stop-tracking=
keycode-toggle=
keycode-toggle-tracking=
keycode-zero=
[Curves-tx_alt]
point-count=1
point-0-x=100
point-0-y=100
[Curves-ty]
point-count=1
point-0-x=100
point-0-y=100
[Curves-ty_alt]
point-count=1
point-0-x=100
point-0-y=100
[Curves-tz]
point-count=1
point-0-x=100
point-0-y=100
[Curves-tz_alt]
point-count=1
point-0-x=100
point-0-y=100
[Curves-rx]
point-count=3
point-0-x=7.1999998092651403
point-0-y=8.7804880142211896
point-1-x=76
point-1-y=80
point-2-x=180
point-2-y=180
[Curves-rx_alt]
point-count=1
point-0-x=180
point-0-y=180
[Curves-ry]
point-count=3
point-0-x=6.9942855834960902
point-0-y=8.7804880142211896
point-1-x=100
point-1-y=100
point-2-x=180
point-2-y=180
[Curves-ry_alt]
point-count=1
point-0-x=180
point-0-y=180
[Curves-rz]
point-count=1
point-0-x=180
point-0-y=180
[Curves-rz_alt]
point-count=1
point-0-x=180
point-0-y=33.365852355957003
[Accela]
ewma=2
rotation-threshold=25
translation-threshold=25
[freepie-udp-tracker]
add-pitch-degrees=0
add-roll-degrees=0
add-yaw-degrees=0
axis-index-x=0
axis-index-y=1
axis-index-z=2
port=5555
[keyboard-shortcuts]
key-alt-center=false
key-alt-toggle=false
key-alt-zero=false
key-ctrl-center=false
key-ctrl-toggle=false
key-ctrl-zero=false
key-index-center=19
key-index-toggle=0
key-index-zero=0
key-shift-center=false
key-shift-toggle=false
key-shift-zero=false
[proto-freetrack]
use-memory-hacks=false
used-interfaces=0
[udp-proto]
ip1=127
ip2=0
ip3=0
ip4=0
port=5556
Sustainable peace with database changes into a Java environment
Sustainable peace for us is remove uncertainty. In this case over database changes the idea Active Record Migrations of Ruby was welcomed.
And what does migration means for us?. Well, it is a convenient way to alter our database schema overtime in a consistent and easy way that removes a lot of uncertainty about database changes in our software development process.
Goal
Our goal will be maintaining the lifecycle of the database according to the development and evolution of the project with an absolute control over the changes.
For this we have to look for a simple tool with a basic group of characteristics as the following ones:
- Works with any database although now our database is MySQL.
- Enable concurrent developers to work independently.
- Enable different development environments.
- Able to integrate with any version control system.
- Able to integrate easily migration tasks into Apache Ant.
- Allow forward and backward migrations and conflicts easily manageable.
We select MyBatis Migrations tool as the best solution for us and a GitHub repository Ant Script to run MyBatis Migrations’ commands as a start line.
Let’s go to the point: How we work with migrations
With these tools we think that a lifecycle of migration may be like this one
The first time
- Create a migrations directory into our project directory.
- Download MyBatis Schema migrations file mybatis-migrations-3.1.1-bundle.zip.
- Create a lib directory and copy
mybatis-3.2.3.jarandmybatis-migrations-3.1.1.jarfiles. - Download Ant tasks build.properties and build.xml files from mybatis-migrations-anttasks-master.zip and rename it as migrations.properties/xml for clearer goals.
- Obviously, this files define ant tasks and basic properties for migrations tool while migrations.properties (comments are included for clearly) defines
# Default environment mybatis.default.environment=development mybatis.dir=migrations mybatis.lib.dir=${mybatis.dir}/lib mybatis.repository.dir=${mybatis.dir}/db # This directory contains your migration SQL files. These are the files # that contain your DDL to both upgrade and downgrade your database # structure. By default, the directory will contain the script to # create the changelog table, plus one empty example migration script. mybatis.scripts.dir=${mybatis.repository.dir}/scripts # Place your JDBC driver .jar or .zip files in this directory. # Upon running a migration, the drivers will be dynamically loaded. mybatis.drivers.dir=${mybatis.repository.dir}/drivers # In the environments folder you will find .properties files that # represent your database instances. By default a development.properties # file is created for you to configure your development time database # properties. # You can also create test.properties and production.properties # files. The properties file is self documented. mybatis.env.dir=${mybatis.repository.dir}/environmentsand migrations.xml defines ant tasks as you can see in the original documentation. Of course, you must rename it as xml file descriptor property to load it
<?xml version="1.0" encoding="UTF-8"?> <project name="MyBatis Migrations" basedir="." default="db:migrate:status"> <property file="migrations/migrations.properties" /> ..... </project> - But, how to install it … It’s easy, basically we have to execute:
$ ant -f migrations.xml db:migrate:init
It creates directories and the initial files as they were defined in migrations.properties as you can see in this output log
Buildfile: /wpr/myproject/migrations/migrations.xml db:migrate:init: [echo] ** Executing "migrate init" on "development" environment ** [java] ------------------------------------------------------------ [java] -- MyBatis Migrations - init [java] ------------------------------------------------------------ [java] Initializing: db [java] Creating: environments [java] Creating: scripts [java] Creating: drivers [java] Creating: README [java] Creating: development.properties [java] Creating: bootstrap.sql [java] Creating: 20131123174059_create_changelog.sql [java] Creating: 20131123174100_first_migration.sql [java] Done! [java] [java] ------------------------------------------------------------ [java] -- MyBatis Migrations SUCCESS [java] -- Total time: 2s [java] -- Finished at: Sat Nov 23 18:41:00 CET 2013 [java] -- Final Memory: 1M/117M [java] ------------------------------------------------------------. BUILD SUCCESSFUL Total time: 3 secondswhile
- environments, scripts and drivers are directories (as seen before).
- README, that explains directories contents as the name suggests.
- bootstral.sql, in which you have to include the database actual schema. You need to start from a known state.
- 20131123174059_create_changelog.sql contains a default control table for migration tool. It’s a price that you have to pay.
- 20131123174100_first_migration.sql will be your first SQL migration file. You can delete it or rename it for clearly although you must keep the format as yyyymmddHHMMss_.
- Keep migrations/db/environment/development.properties database properties for development environment
## JDBC connection properties. driver=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/<databaseName> username=root password=root
- Add others environment properties files to each migrations/db/environment/<environment>.properties if you need.
- As last step, put your actual database schema into bootstrap.sql file.
Day by day
Among all migrate commands we normally use
- Create one or many migrations doing db:migrate:new.
- Apply migrations to database doing db:migrate:up.
Optional steps included:
- Revert migrations if necessary to solve conflicts. Any mistake has an easy solution with db:migrate:down .. but remember that it is by single steps.
- Apply pending migrations out of order if it’s safe to do so with db:migrate:pending or db:migrate:version. Actually, if you want to execute those tasks you will have to add the code belong into migrations.xml
<?xml version="1.0" encoding="UTF-8"?> <project name="MyBatis Migrations" basedir="." default="db:migrate:status"> .... <!-- $ migrate pending --> <target name="db:migrate:pending" description="Runs all pending migrations regardless of their order or position in the status log"> <migrate command="pending" environment="${environment}" /> </target> <!-- $ migrate version --> <target name="db:migrate:version" description="Migrate the schema to any specific version"> <input addproperty="specific.version" message="Specific version to migrate:" /> <migrate command="version" environment="${environment}"> <extraarguments> <arg value="${specific.version}" /> </extraarguments> </migrate> </target> </project> - Generate migration scripts to be run “offline” in environments that are beyond your control.
- Get the status of the system at any time doing db:migrate:status.
We hope you find useful our solution, all comments are welcomed and apologies for my english.
AutoBean, JSON con GWT
 En GWT a la hora de interactuar desde la parte cliente con el servidor utilizamos los servicios y estamos acostumbrados a enviar objetos y recibir objetos. Cuando trabajamos con formularios podemos seguir aprovechándonos de esta característica enviando desde el servidor objetos convertidos a JSON y reconstruyéndolos en el cliente con AutoBean.
En GWT a la hora de interactuar desde la parte cliente con el servidor utilizamos los servicios y estamos acostumbrados a enviar objetos y recibir objetos. Cuando trabajamos con formularios podemos seguir aprovechándonos de esta característica enviando desde el servidor objetos convertidos a JSON y reconstruyéndolos en el cliente con AutoBean.
Antes de meternos en faena, formularios en GWT
Para entender mejor el uso que vamos a explicar de los AutoBean’s, vamos a describir brevemente como funcionan los formularios en GWT
El constructor sin parámetros de FormPanel, crea un iframe para este formulario de forma que cuando hagas submit se hará sobre este iframe evitando que se recargue toda la página. Cuando el servidor responda a esta petición, el formulario lanzará el evento onSubmitComplete y se podra recuperar el texto devuelto con el método getResults() del evento SubmitCompleteEvent. Este es el constructor que nosotros vamos a usar en esta entrada.
También hay otros constructores que te permiten relacionar tu formulario con un iframe, pero en estos casos el evento onSubmitComplete no es lanzado y hay que utilizar otros métodos para recuperar la respuesta del servidor.
Manos a la obra
Primero vamos a hacer un breve descripción de los pasos que va a dar nuestra aplicación:
- Se hace submit de un formulario
- El servidor procesa la petición y se genera un objeto de respuesta
- Con AutoBean serializamos el objeto en JSON y lo enviamos al cliente
- El cliente recupera el texto JSON y reconstruye el objeto inicial con AutoBean
Requisitos
El AutoBean que vamos a definir se utiliza tanto en la parte de cliente como en la parte de servidor, tiene que estar en una paquete compartido de GWT.
Los objetos que vamos a serializar (y deserializar) tienen que ser implementaciones de una interfaz y esa interfaz tiene que definir un bean, es decir, sus métodos tienen que ser getters (getX e isX). AutoBean trabaja con interfaces de objetos.
En el gwt.xml tenemos que importar el módulo de AutoBean:
<inherits name="com.google.web.bindery.autobean.AutoBean" />
Y tenemos que añadir la librería gwt-servlet-deps.jar al classpath de la aplicación.
AutoBeanFactory
Para crear AutoBean’s tenemos que definir una interfaz que extienda de la interfaz AutoBeanFactory y para cada objeto que vamos a serializar tenemos que tener un método en esa interfaz que devuelva un AutoBean parametrizado con la interfaz de dicho objeto que vemos a serializar.
public interface MyAutoBeanFactory extends AutoBeanFactory {
public AutoBean<IMyBean> makeMyBean();
}
MyAutoBeanFactory es la interfaz que vamos a utilizar para obtener los AutoBean’s
IMyBean es la interfaz que debe implementar el bean que vamos a querer serializar.
Parte Servidor
Para obtener el objeto factoría que vamos a utilizar para obtener los AutoBean’s, llamamos al método create de la clase AutoBeanFactorySource pasándole la clase de la interfaz de nuestra factoría. Ahora podemos crear el AutoBean para el objeto que vamos a serializar, donde myBeanObject es el objeto que vamos a serializar. Es importante poner como contentType text/html para que el navegador lo pinte tal y como viene (no intente formatearlo de alguna manera).
MyAutoBeanFactory beanFactory = AutoBeanFactorySource.create(MyAutoBeanFactory.class);
AutoBean<IMyBean> bean = beanFactory.create(IMyBean.class, myBeanObject);
String json = AutoBeanCodex.encode(bean).getPayload();
BufferedWriter bf=new BufferedWriter(response.getWriter());
response.setContentType("text/html");
bf.write(json);
bf.flush();
bf.close();
este código serializaría el objeto myBeanObject y lo enviaría como respuesta al cliente. (El objeto response es de la clase HttpServletResponse).
Parte Cliente
Ahora vamos a ver el código de como recuperar el texto que ha enviado el servidor como respuesta del submit del formulario y convertir el texto JSON en nuestro objeto a través de AutoBean.
formPanel.addSubmitCompleteHandler(new SubmitCompleteHandler() {
@Override
public void onSubmitComplete(SubmitCompleteEvent event) {
MyAutoBeanFactory beanFactory = GWT.create(MyAutoBeanFactory.class);
String json = event.getResults();
AutoBean<IMyBean> autoBeanClone = AutoBeanCodex.decode(beanFactory, IMyBean.class, json);
IMyBean bean = autoBeanClone.as();
...
}
});
En el código de ejemplo, cuando se lanza el evento SubmitCompleteEvent del formulario, creamos el objeto MyAutoBeanFactory y el texto JSON del servidor, utilizamos el método AutoBeanCodex.decode(…) que nos recupera el AutoBean para nuestra interfaz.
Un posible uso de todo esto es a la hora de tener que subir un archivo al servidor. En este caso estamos casi obligados a usar un formulario y esta podría ser una buena forma de procesar la respuesta del servidor.
Entender, detectar y localizar memory leaks en aplicaciones web (java.lang.OutOfMemoryError)
Cuando aparece el mensaje java.lang.OutOfMemoryError, en cualquiera de sus variantes, en los logs de Tomcat o el contenedor de Servlets que uses, es muy posible que alguna de las aplicaciones desplegadas contenga un memory leak. Y es que, a pesar de la existencia del Garbage Collector (GC), que podría hacernos pensar lo contrario, las aplicaciones Java pueden crear memory leaks.
En este artículo hablaremos de los distintos tipos de memory leak y sobre cómo detectarlos. Y, lo que es mas importante, proporcionaremos herramientas para localizar las causas que los provocan y consejos para evitarlos y solucionarlos. Prestaremos especial atención a los
Tomcat Classloader Memory Leaks, responsables del famoso (infame) error java.lang.OutOfMemoryError: PermGen space failure.
Motivos principales por los que puede aparece el error java.lang.OutOfMemoryError
La excepción OutOfMemoryError indica que la máquina virtual no dispone de la memoria necesaria para crear un objeto. Esto puede deberse a varios motivos, y no quiere decir necesariamente que la aplicación contenga un memory leak. Es posible que, simplemente, la que memoria asignada a la máquina virtual se haya agotado.
Por el contrario, un memory leak consiste en que la aplicación reserva memoria que luego no es posible liberar. En el caso concreto de aplicaciones Java, la aplicación reserva memoria que el GC no podrá liberar. La consecuencia es que, conforme transcurre el tiempo de ejecución, la aplicación consume mas y mas memoria, puesto que no es capaz de liberar la que ya no usa (o, al menos, no toda). En el momento en que el sistema se queda sin memoria disponible se produce el error OutOfMemoryError. En el caso de Tomcat, la única opción que nos queda, llegados este punto, es el reinicio.
En estos casos, la solución de incrementar la memoria del heap, o la de la generación PermGen, como se verá a continuación, simplemente retrasa el tiempo necesario para que la memoria se agote, pero NO soluciona el problema.
Un procedimiento sencillo, por lo visual, aunque grosero, de determinar si una aplicación contiene memory leaks consiste en observar el perfil del consumo de memoria de la aplicación. Esta operación es sencilla si se usa un profiler. Un profiler permite determinar, entre otras cosas (como el consumo de CPU), la memoria usada por la aplicación en tiempo real. Un ejemplo es VisualVM.

En el caso de Java, el perfil de consumo de memoria de una aplicación a lo largo del tiempos será similar a unos dientes de sierra. La explicación es que la aplicación irá reservando la memoria que necesite para atender las peticiones que recibe. Esto se traduce en un tramo ascendente temporalmente. En el momento en que se ejecuta el GC, se libera toda la memoria que ya no se necesita, por lo que la cantidad de memoria usada por la aplicación desciende abruptamente.
Si se precisara de un análisis mas detallado, habría que usar funcionalidad mas avanzada del profiler, como los volcados de memoria (Heap Dump) o la comparación del uso de memoria en distintos instantes.
Un artículo bastante completo sobre los usos de visualVM puede encontrarse en este artículo de JavaCodeGeeks.
En el caso de que la aplicación no contenga ningún memory leak, la forma de solucionar el problema java.lang.OutOfMemoryError es sencilla: aumentar la memoria de la que dispone la JVM. Ni que decir tiene que un paso previo debería ser revisar el código de la aplicación para confirmar que la memoria se usa eficientemente !!
En el caso particular de encontrarnos con el mensaje java.lang.OutOfMemoryError: Java heap space, se debe aumentar la memoria asignada al heap. Las opciones de la VM que permiten modificar el tamaño del heap son –Xmx (tamaño máximo del heap) y –Xms (tamaño mínimo del heap o, mas intuitivamente, memoria reservada inicialmente). Si la cantidad de memoria no es problema, no es mala idea asignar el mismo valor a las dos opciones, puesto que puede ayudar a mejorar el rendimiento. Por ejemplo, para asignar 256 M:
java -Xms256m -Xmx256m
En el caso de Tomcat deben modificarse las variables de entorno . Una forma es editar el archivo setenv.sh (setenv.bat en sistemas Windows). Por ejemplo:
$ cat setenv.sh export JAVA_OPTS=" -Xms256m -Xmx256m"
Por el contrario, cuando el mensaje de error hace referencia a la generación PermGen (java.lang.OutOfMemoryError: PermGen space failure), el problema es distinto. En este caso la memoria que se agota no es la heap en general, sino la zona particular asignada a la Permanent Generation. En esta zona se almacena metainformación sobre las clases que la JVM necesita (por ejemplo, los objetos Class, Method y Field de las clases que cargan). Es posible llegar al límite de memoria asignado por defecto a esta zona cuando se usan librerías mas o menos pesadas (implementaciones de JPA, WebServices,…) debido a la cantidad de clases que pueden llegar a cargar.
Aumentar el tamaño del heap no ayudará en este caso: seguirá produciéndose el mismo error. La solución consiste en aumentar el tamaño del espacio asignado específicamente a la generación PermGen. Para ello se dispone de la opción -XX:MaxPermSize, que permita especificar el tamaño de la memoria asignada a dicha generación.
Todas estas opciones (como todas las que comienzan por -X o -XX) no son estándares y, aunque funcionan en la JVM HotSpot de Sun (perdón, Oracle), no se garantiza su soporte en otras implementaciones.
Cuando se trata del primer tipo comentado de memory leaks, los que agotan la memoria mediante la creación de nuevas instancias mientras que el GC es incapaz de eliminar instancias antiguas, no hay diferencia alguna entre una aplicación de Desktop y otra desplegada en cualquier servidor de aplicaciones o contenedor de Servlets.
Sin embargo, en el caso de aplicaciones desplegadas en Tomcat (y presumiblemente, varios otros contenedores de Servlets), debido a la gestión que se realiza de las aplicaciones desplegadas, es relativamente sencillo, si no se tiene cuidado, generar memory leaks del tipo que acaban consumiendo la memoria asignada a PermGen. Además, el mecanismo por el que se crean estos leaks es sutil y su detección y, sobre todo, la localización de la causa que lo provoca, no es sencilla si no se dispone de las herramientas adecuadas.
En este tipo de memory leaks, que suelen conocerse como Classloaders Memory Leaks, se centra el resto del artículo.
Tomcat Classloader Memory Leaks
El síntoma mas común que lleva a pensar en un memory leak de este tipo es que se agota el espacio asignado a la PermGen tras varios deploys y undeploys, dejando el conocido mensaje en el log (java.lang.OutOfMemoryError: PermGen space failure) y sin mas solución que reiniciar Tomcat.
El motivo por el que suelen aparecer este tipo de leaks tiene que ver con la gestión de las aplicaciones que implementa Tomcat. Dicha gestión se basa en la creación de varios classloaders organizados jerárquicamente en forma similar a un árbol. Cada aplicación desplegada tiene su propio classloader (clase WebappClassLoader), pero estos web application classloaders tienen un modelo de delegación distinto al usual: cuando se necesita crear una clase desde una aplicación web se busca primero en los repositorios locales (de la propia aplicación), en lugar de delegar la búsqueda en el classloader padre (excepto algunas excepciones, como las clases que forman parte de la JRE).
Se recomienda consultar los detalles en la doc de Tomcat.
Esta característica permite que, cuando se realiza el repliegue (undeploy) de una aplicación, el classloader se descarta, y con él todas las clases cargadas por él, de manera que dicho repliegue no afecta a las demás aplicaciones. Así se consigue que se puedan tanto desplegar (deploy) y replegar aplicaciones sin necesidad de reiniciar Tomcat y sin afectar a las demás aplicaciones.
Pero, a su vez, esta característica abre la puerta a posibles memory leaks: si en un classloader por encima del nivel del web application classloader correspondiente se mantiene alguna referencia a alguna clase cargada por dicho web application class loader, el GC no lo eliminará. Así, quedará en memoria toda la metainformación (objetos Class, Method, Field, …) de las clases cargadas por dicho classloader. Dependiendo de las políticas de prevención de leaks del contenedor, podrían quedar también objetos referenciados desde dicho web application classloader.
En función de la importancia, en términos de memoria, del leak, el contenedor soportará mas o menos repliegues y despliegues de la aplicación antes de soltar el mensaje java.lang.OutOfMemoryError: PermGen space failure en el log.
El mecanismo de generación de memory leaks está muy bien explicado en el artículo Classloader leaks: the dreaded “java.lang.OutOfMemoryError: PermGen space” exception
Como el asunto es relativamente complejo, vamos a ilustrarlo con un pequeño ejemplo. Para ello, añadiremos al directorio de librerías comunes del contenedor (en Tomcat 6 es el directorio lib) un jar conteniendo la clases LeakerRegister y el interfaz Salutation:
package com.wordpress.tododev.leaker.register;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class LeakerRegister {
private static final Map<String, Class<? extends Salutation>> implementations = new HashMap<String, Class<? extends Salutation>>();
private final Log log = LogFactory.getLog(getClass());
public void register(String implName, Class<? extends Salutation> clazz){
log.debug("Received register request for " + implName + ", implementation " + clazz.getName());
if (!implementations.containsKey(implName))
implementations.put(implName, clazz);
else
log.debug("already exists " + implName);
}
public void cleanup(){
implementations.clear();
}
private Salutation createInstance(Class<? extends Salutation> clazz){
if (clazz == null)
return null;
Salutation impl;
try {
impl = clazz.newInstance();
return impl;
} catch (InstantiationException e) {
log.debug("Failed to instantiate " + clazz.getName(), e);
return null;
} catch (IllegalAccessException e) {
log.debug("Failed to instantiate " + clazz.getName(), e);
return null;
}
}
public Salutation getImplementation(String implName){
return createInstance(implementations.get(implName));
}
}
//// Salutation Interface
package com.wordpress.tododev.leaker.register;
public interface Salutation {
public String salute();
}
El objetivo de la clase LeakerRegister es mantener un registro de implementaciones para el interfaz Salutation. Para ello usa un Map estático (implementations) donde almacena las clases de las implementaciones registradas. Cuando se le solicita una implementación, crea una instancia de la clase correspondiente.
Por otra parte, crearemos un war, que será la aplicación web que se despliegue en el contenedor de Servlets, con las siguientes clases:
package com.wordpress.tododev;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import com.wordpress.tododev.leaker.register.LeakerRegister;
import com.wordpress.tododev.leaker.register.Salutation;
public class Leaker extends HttpServlet{
private static final long serialVersionUID = 6549546920601945792L;
private static final String PARAM_LANG = "lang";
private static final String LANG_ES = "es";
private static final String LANG_EN = "en";
private static final String LANG_IT = "it";
private final Log log = LogFactory.getLog(getClass());
private final LeakerRegister register = new LeakerRegister();
private Salutation getInstance (String implName){
return register.getImplementation(implName);
}
@Override
public void init() throws ServletException {
super.init();
registerImplementations();
}
private void registerImplementations(){
// TODO load from properties, servlet context, ... whatever
register.register(LANG_ES, SalutationEsp.class);
register.register(LANG_EN, SalutationEng.class);
register.register(LANG_IT, SalutationIta.class);
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
final Salutation salutation = getInstance(req.getParameter(PARAM_LANG));
if (log.isDebugEnabled()){
log.debug("Provided lang " + req.getParameter(PARAM_LANG));
log.debug("Got implementation " + salutation);
}
resp.getOutputStream().println((salutation == null)?"!!??":salutation.salute());
}
}
// Saludo en español
package com.wordpress.tododev;
import com.wordpress.tododev.leaker.register.Salutation;
public class SalutationEsp implements Salutation {
@Override
public String salute() {
return "Hola !!";
}
}
// Saludo en inglés
package com.wordpress.tododev;
import com.wordpress.tododev.leaker.register.Salutation;
public class SalutationEng implements Salutation {
@Override
public String salute() {
return "Hi !!";
}
}
// Saludo en italiano
package com.wordpress.tododev;
import com.wordpress.tododev.leaker.register.Salutation;
public class SalutationIta implements Salutation {
@Override
public String salute() {
return "Ciao !!";
}
}
Como puede verse, lo único que hace es registrar las implementaciones para el saludo para los idiomas español, inglés e italiano y, posteriormente, comienza a atender peticiones. Hemos intentado que la lógica sea lo mas simple posible para no distraer la atención del tema que nos ocupa.
Nota: se ha usado Tomcat en su versión 6.0.24. El soporte para la detección e incluso solución de este tipo de leaks en Tomcat 6 y Tomcat 7 está en continua mejora, por lo que es posible que no se pudiera reproduciren versiones posteriores.
Detección de Tomcat Classloader Memory Leaks
Una vez que se conoce el motivo por el cual suelen generarse estos leaks es relativamente sencillo detectarlo: en algún sitio del heap tendremos una instancia de la clase WebappClassLoader que no debería estar. Un profiler facilitará la búsqueda de dicho classloader. En nuestro caso usaremos VisualVM.
Una vez tengamos la aplicación desplegada y se hayan hecho varias peticiones, haremos un volcado de memoria (Heap Dump). En dicho dump vamos a buscar las instancias de la clase org.apache.catalina.loader.WebappClassLoader. Para buscar las instancias hay que seleccionar la pestaña Classes e introducir la expresión regular a buscar (por ejemplo, webappclassloader).

A continuación, hacemos un repliegue y despliegue de la aplicación y haremos un nuevo volcado de memoria. En este caso aparece una instancia de mas, aunque el número de aplicaciones desplegadas es el mismo que en caso anterior: tenemos un memory leak.

Haciendo doble click sobre la clase WebappClassLoader aparecerán todas las instancias de la misma. Debería haber una por cada aplicación desplegada en Tomcat. Seleccionamos cada instancia de la clase WebappClassLoader para inspeccionar los distintos miembros.
La instancia responsable del leak debe contener el valor false en el campo booleano started. Es un indicio claro de que tenemos un leak de classloaders (a no ser que tengamos aplicaciones detenidas intencionadamente). Es decir, alguna clase externa a nuestra aplicación mantiene una referencia a alguna clase de la aplicación, de manera que el GC, al encontrar referencias a dicha clase, no la elimine. Esto provoca que tampoco elimine el classloader, que mantiene referencias a todas las clases de la aplicación. Así que, dependiendo de la aplicación, el leak podría ser bastante importante.

Una forma de tener algo mas de seguridad sobre si realmente es un leak o no es echar un vistazo al Vector classes, donde aparecen las clases cargadas por el classloader correspondiente, y ver si se corresponden con las de nuestra aplicación.
En nuestro caso, el leak lo introduce el Map estático implementations de la clase LeakerRegister. Al ser un jar común al contenedor de aplicaciones, las clases serán cargadas por un classloader superior al WebappClassLoader. Cuando, desde la aplicación (Leaker servlet), se crea la primera instancia de LeakerRegister, se inicializa el miembro implementations. A continuación, al registrar las diferentes implementaciones, se almacenan en dicho Map referencias a cada una de las implementaciones de Salutation, que son cargadas por el WebappClassLoader de la aplicación.
Al ser un Map estático, perdura incluso cuando se repliega (elimina) la aplicación y, por lo tanto, la única instancia de LeakerRegister. Al mantener dicho Map referencias a clases cargadas con el WebappClassLoader, el GC no puede recolectar y eliminar dicho classloader, con lo que aparece el leak.
Encontrando la causa del memory leak
Memory leak confirmado. Ahora se trata de encontrar desde dónde se hace esa referencia a alguna clase cargada por el WebappClassLoader que impide que el GC lo elimine. La idea es sencilla, pero prácticamente imposible de llevar a cabo usando únicamente VisualVM.
Afortunadamente, disponemos de la herramienta jhat que será de gran ayuda en este proceso. Viene incluido en el JDK6, pero debemos usar una versión relativamente reciente para asegurarnos de que incluye la funcionalidad que necesitamos. La ventaja de jhat es que permite navegar por los paths de referencias, lo que hace mas sencillo identificar la causa del memory leak. Esta herramienta trabaja con volcados de memoria (Heap Dumps) por lo que debemos guardar a disco el Head Dump que creamos con visualVM que contiene el leak.
Los pasos a seguir para encontrar la causa del leak son:
- Arrancar jhat: jhat -J-Xmx512m heapdump-XXXXXXXX.hprof, donde el archivo con extensión .hprof es el heapdump generado con visualVM.
- Abrir la url http://localhost:7000 en un navegador web. Veremos una lista con todas las clases presentes en el dump.
- Buscar alguna de las clases de nuestra aplicación, que no deberían estar ahí si hubieran sido eliminadas por el GC, ya que el Heap Dump se realizó despues de hacer un undeploy, sin hacer un deploy a continuación.
- Seleccionar el link del ClassLoader (Loader Detail / ClassLoader), que nos llevará a la instancia del ClassLoader que mantiene alguna referencia a nuestra clase. Se puede comprobar que campo started está a false.
- Seleccionar Chains from Rootset / Exclude weak refs. Nos aparecen todas las clases que contienen al classloader seleccionado en el path de sus referencias !!
De esta forma podemos saber que clases mantienen referencias al classloader que el GC no pudo eliminar. No deberían ser muchas, porque entonces tendríamos varias causas distintas para el leak. Ahora es cuestión de investigar por qué se mantienen dichas referencias y solucionarlo. Muchas veces la solución pasa por añadir código que “haga limpieza” en el ServletContextListener de la aplicación, sobre todo cuando el origen del problema se localiza en una librería externa.
Esto viene también, muchísimo mejor explicado, en el artículo How to fix the dreaded “java.lang.OutOfMemoryError: PermGen space” exception (classloader leaks)
En nuestro caso, en el Heap Dump encontramos las siguientes clases:

Seleccionando una de ellas, podemos llegar al Classloader conflictivo. Es ahora cuando seleccionamos Chains from Rootset / Exclude weak refs. Y se obtiene:

Puede apreciarse como se mantiene una referencia al Classloader a través de una entrada del HashMap de LeakerRegister. En concreto, hemos localizado la referencia a través de la entrada correspondiente a la clase SalutationIta.
Nota: Es posible que jhat también esté en versiones anteriores del JDK, pero no nos serviría para nuestro propósito, puesto que dichas versiones tienen una limitación que no permite encontrar el path completo de referencias.
Posibles soluciones
Obviamente, las soluciones dependen de la causa del leak. En nuestro caso, existen al menos dos formas distintas de afrontar el problema. La primera de ellas es aplicable cuando todo el código, tanto el del jar como el de la aplicación web, está bajo nuestro control. En ese caso, la solución pasa por hacer el Map implementations de LeakerRegister un miembro de la clase en lugar de usarlo como estático. De esta forma, al eliminar la referencia a la instancia LeakerRegister desde el servlet Leaker se elminará el Map implementations, con lo que no quedarán referencias a las diferentes implementaciones de Salutation. En este caso, se podría aprovechar para dotar a LeakerRegister del soporte para genéricos, de manera que sería válido para cualquier tipo de implementaciones, y no sólo con las de el interfaz Salutation. Quedaría algo así:
package com.wordpress.tododev.leaker.register;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class LeakerRegister<T> {
private final Map<String, Class<? extends T>> implementations = new HashMap<String, Class<? extends T>>();
private final Log log = LogFactory.getLog(getClass());
public void register(String implName, Class<? extends T> clazz){
log.debug("Received register request for " + implName + ", implementation " + clazz.getName());
if (!implementations.containsKey(implName))
implementations.put(implName, clazz);
else
log.debug("already exists " + implName);
}
public void cleanup(){
implementations.clear();
}
private T createInstance(Class<? extends T> clazz){
if (clazz == null)
return null;
T impl;
try {
impl = clazz.newInstance();
return impl;
} catch (InstantiationException e) {
log.debug("Failed to instantiate " + clazz.getName(), e);
return null;
} catch (IllegalAccessException e) {
log.debug("Failed to instantiate " + clazz.getName(), e);
return null;
}
}
public T getImplementation(String implName){
return createInstance(implementations.get(implName));
}
}
// Servlet Leaker
package com.wordpress.tododev;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import com.wordpress.tododev.leaker.register.LeakerRegister;
import com.wordpress.tododev.leaker.register.Salutation;
public class Leaker extends HttpServlet{
private static final long serialVersionUID = 6549546920601945792L;
private static final String PARAM_LANG = "lang";
private static final String LANG_ES = "es";
private static final String LANG_EN = "en";
private static final String LANG_IT = "it";
private final Log log = LogFactory.getLog(getClass());
private final LeakerRegister<Salutation> register = new LeakerRegister<Salutation>();
private Salutation getInstance (String implName){
return register.getImplementation(implName);
}
@Override
public void init() throws ServletException {
super.init();
registerImplementations();
}
private void registerImplementations(){
// TODO load from properties, servlet context, ... whatever
register.register(LANG_ES, SalutationEsp.class);
register.register(LANG_EN, SalutationEng.class);
register.register(LANG_IT, SalutationIta.class);
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
final Salutation salutation = getInstance(req.getParameter(PARAM_LANG));
if (log.isDebugEnabled()){
log.debug("Provided lang " + req.getParameter(PARAM_LANG));
log.debug("Got implementation " + salutation);
}
resp.getOutputStream().println((salutation == null)?"!!??":salutation.salute());
}
}
Sin embargo, en ocasiones, el jar podría ser una librería que no hayamos desarrollado nosotros. En este caso, el mismo problema se podría abordar desde otro enfoque: crear un Servlet Context Listener que eliminase todos los elementos del Map implementations, llamando al método cleanup de LeakerRegister, al destruirse el contexto. De esta forma también se eliminan las referencias a las clases cargadas por el WebappClassLoader.
En cualquier caso, aunque la solución depende completamente de la causa del memory leak y no hay recetas universales (aunque sí varias recomendaciones, como éstas de la Tomcat Wiki), esperamos que al menos haya servido para identificar los memory leaks, entender el mecanismo por el que se producen, e identificar las posibles causas.
Algunos ejemplos de leaks conocidos son el del JDBC Driver Manager, o el Query Timeout del Connector/J de MySQL. ¿ Con cuáles te has encontrado tú ? ¿ Cómo los has solucionado ?
